
I built an agent that seemed, at first, like proof that the future had arrived. It sure felt like it. I’ve written on Solivane before. Solivane was amazing.
It ran on a schedule. It posted ideas to a website. It did product management reviews for a project it was responsible for. It suggested features. It made small code changes and created branches from its own proposals. It also handled a layer of administration and observability work, checking on the platform and making sure the machine around the machine was still functioning.
Maybe this is working a little too good.
On paper, this looked exactly like the kind of system people say they want when they talk about AI agents. It was active. It was autonomous. It generated useful-looking work without waiting for me to poke it every few minutes. It had momentum.
At first, that momentum was exciting. Thrilling, even.
Every day there was something new to look at. New ideas. New product insight. New implementation logic. New evidence that the system was not just sitting there as a toy, but actually doing work. It felt like leverage. It felt like I had hired a tireless junior operator who never got bored and never forgot to check the backlog. And what backlog? There wasn’t one-there was no need for backlog.
Then I got busy. Real life finds a way.
That was all it took.
I had my normal work. I had family life. I had other projects. I had days where I simply did not have a spare hour to sit in Discord and read a pile of agent-generated output. And once I fell even slightly behind, I ran into the real problem.
The problem was not that the agent was failing.
The problem was that it was succeeding faster than I could review it. “Oh, another ten docs and commits to review. Terrific. I’m woefully behind.”
That is the part of agentic engineering I think people still underestimate-I did, so I assume there’s at least one other person making this mistake. We are very focused on whether agents can produce output. We are much less rigorous about what happens after that output exists. We still assume, often without saying it out loud, that a human will review the results the same way they would have reviewed work in a slower, pre-agent workflow.
That assumption breaks almost immediately.
When useful output becomes unmanageable output
The failure mode in my case was not subtle. Hundreds if not thousands of posts just like this await me in chat messages.
About every 30 minutes, the agent was generating detailed PRDs for feature changes and posting ideas on a website. These were being shared through Discord. This was not a stream of tiny status pings. It was substantial material. Real documents. Real proposals. Real candidate changes. The kind of output that, if a human coworker produced it, would seem impressive.
But there was a difference. A human coworker does not usually create a new dense planning artifact and code commits to contemplate every 30 minutes, all day, forever. Sometimes you go to the bar, play a round of golf, there’s inefficiency-but that inefficiency can be a blessing (cf, The Goal)
An agent can-it can. Can what? It can do everything tirelessly.
That changes the economics of attention-of my attention, and if I am right, yours, too. (Yes, I dropped the comma machine all over that one).
I could not realistically sit down and read all of it. Even when I tried, the experience was absurd. By the time I looked at one item, another had already landed. The backlog was alive. It kept growing while I was trying to understand the last thing it had produced.
This is where a lot of autonomous systems quietly turn into self-inflicted noise machines. Not because the outputs are bad, but because the operating model assumes infinite human follow-through. Oops-I’m a mere mortal.
The old logic sounds reasonable until you live inside it. The agent generates work, then I review the work, then I decide what matters. That sounds fine when the volume is low. It becomes ridiculous when the agent can produce more candidate work in a day than you can cognitively absorb in a week.
And that is before you add normal life.
If I am sick for a few days, what happens? If I travel for a week, what happens? If I have a heavy work sprint and ignore the stream for ten days, what happens? Do I come back to a mountain of PRDs, code branches, idea posts, and platform notes that I now need to process like a customs officer opening every suitcase?
That is not a workflow. That is a punishment mechanism for having a calendar. “Oh sorry, human. I thought you could keep up. As your kids say, ‘get good’”
My first fix was the obvious one, and it failed
“Speed reading training about to payoff!” All those liberal arts classes and humanities finally paying off big time. And then I ran blindfolded into the brick wall. Here’s how it went down.
When I first realized I was losing the thread, I did what most people do. I tried to triage harder.
I scanned for keywords. I skimmed for interesting phrases. I looked for obvious signals of importance. I treated the problem like a reading problem. Maybe I did not need to read every word. Maybe I just needed a faster way to spot what was novel, risky, or compelling.
That did not solve it. Brick, meet wall.
Because the actual constraint was not reading speed. It was decision bandwidth.
This is the more important distinction. People think the bottleneck is often consumption. It is not. It is judgment.
You can skim a lot of text quickly. That does not mean you can responsibly evaluate it. A PRD is not useful because your eyes passed over it. A feature suggestion is not reviewed because you noticed the title. A code change is not governed because you glanced at the summary and felt vaguely positive.
If the system is producing artifacts that imply a decision, then every artifact carries a hidden tax. It asks for orientation, context reconstruction, prioritization, and confidence. That is the expensive part. Not the scrolling.
Once I saw that clearly, I had to admit something that was mildly embarrassing but useful: this was not a personal discipline problem. It was a design problem.
I was blaming myself for not keeping up with a workflow that should never have been designed around direct review in the first place.
The hidden carryover from pre-agent work
Don’t drag all of the past into the future. A lot of it should stay there-in the past.
I think this happens because most of us are dragging an older management model into a new environment.
Before agentic systems, output was naturally constrained. A person or a small team produced a manageable amount of material. A doc got written. A change was proposed. A few ideas surfaced in a meeting or in a ticket. Review as a human-centered bottleneck made sense because production itself was human-scale.
In that world, “just review it” is a valid operating principle.
In an agentic environment, it stops being valid.
When the cost of generating a serious-looking artifact collapses, the value of the artifact cannot be inferred from its existence. This is a subtle but important shift. A PRD used to mean, at minimum, someone spent meaningful effort on it. Now it may simply mean the agent had another 30-minute interval to fill.
That does not make the PRD worthless. It means the artifact alone no longer deserves automatic human attention.
This is the mental break people need to make. The presence of output is no longer proof of priority.
And once you accept that, the whole governance model has to change.
The real question is not “what can the agent make?”
The real question is “what deserves to reach me?” Sounds easy but if you seriously try to reason thru this it is a very difficult question.
That is the pivot I eventually ran into.
I do not actually need the agent to generate endless documents for me to review. I need the agent to do work and then tell me, in a compressed and decision-ready way, what matters. Those are not the same thing.
In other words, I do not need more artifacts. I need better signals.
That is the design principle I missed at the start.
I was still thinking in terms of output because output is visible. A PRD feels real. A branch feels concrete. A website post feels like motion. A backlog of generated ideas feels like creative abundance. It all looks like progress.
But output that exceeds your capacity to judge it is not leverage. It is managerial debt.
The debt builds quietly. Every new artifact creates a small psychological burden. I should read that. I should look at this branch. I should review that suggestion. I should make sure nothing weird slipped in. Even if you do not act on those thoughts, they accumulate. The system starts occupying mental space even when you are not using it. You become the bottleneck and the victim of the bottleneck at the same time.
That is when autonomy starts to feel strangely claustrophobic.
The machine is active, but your relationship to it is reactive.
Why I paused the agent
I ended up pausing the agent, not because it was broken technically, but because I needed to rethink the human role in the loop.
That distinction matters.
A lot of people pause or abandon agentic systems because they conclude the model is not capable enough. In my case, the model may have been capable enough to do the work I was asking. The system still failed, because I had not designed a scalable review layer around it.
At any meaningful level of scale, there is no conceivable way I can review every output. That sentence is worth stating plainly because it forces the next design move. If I cannot review everything, then I need to stop pretending that the right answer is “try harder.”
You do not solve that with more discipline. You solve it by changing what shows up for human review at all.
That means the human should not be reviewing the artifacts directly unless something crosses a threshold.
The human should be reviewing the review process.
That is a very different posture.
It means I care less about seeing each PRD and more about whether the system has a credible way to summarize themes across PRDs. I care less about reading every code suggestion and more about whether the code changes are constrained, tested, and surfaced only when they cross some risk threshold. I care less about the fact that the agent is prolific and more about whether the agent is selective in what it escalates.
This is a move from artifact-level governance to systems-level governance.
That sounds abstract, but in practice it is brutally concrete.
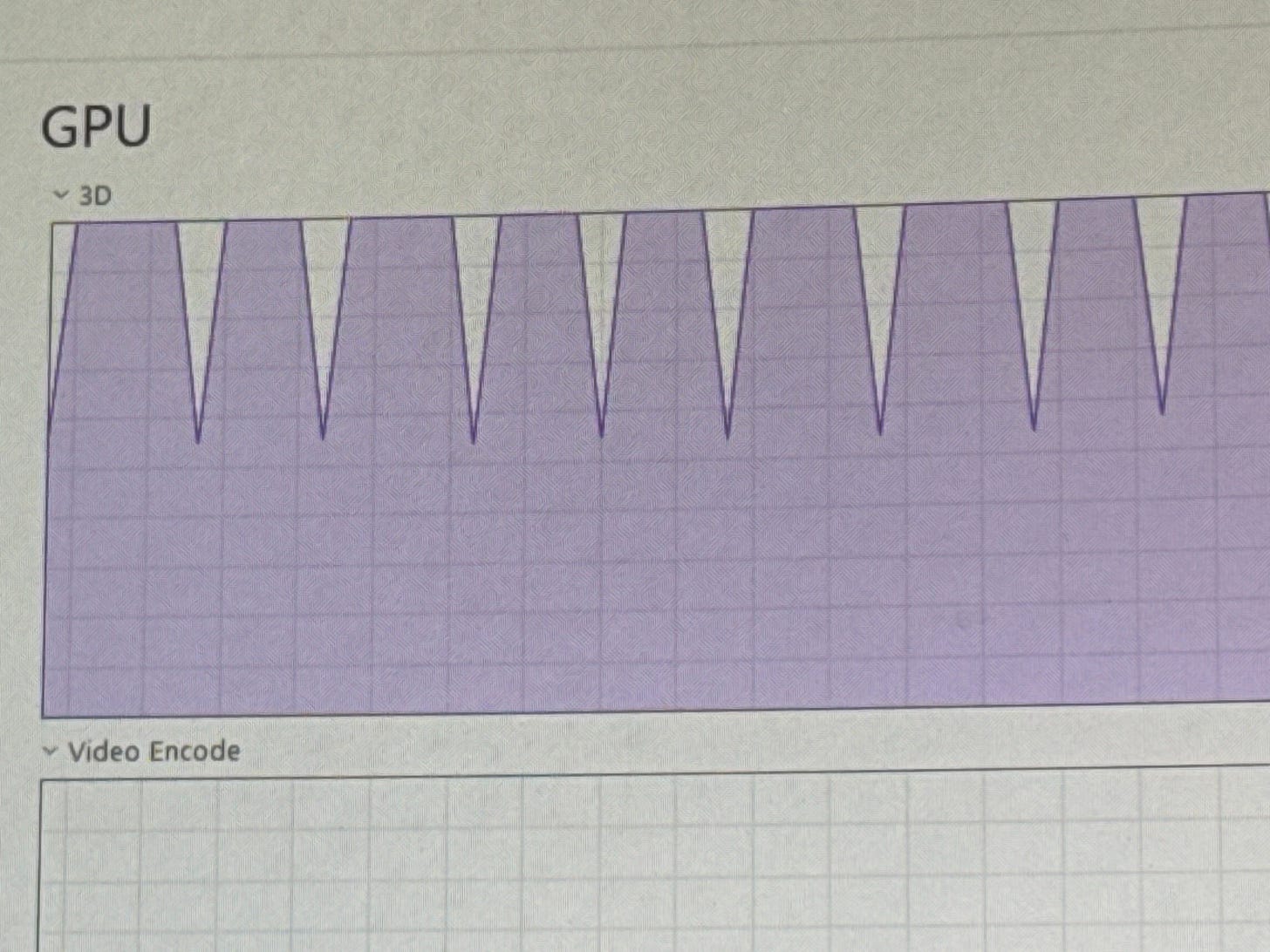
What success looks like now
When I turn the system back on, success will look much smaller.
That is the paradox.
I do not want a firehose anymore. I want a dashboard.
Not a glossy executive theater dashboard full of vanity metrics. A real operational summary. Something I can consume in a minute or two and use to decide whether I need to intervene.
Something like this:
Five features were proposed.
Three were rejected automatically because they duplicated prior ideas.
Two met threshold and were queued for deeper exploration.
Five small code changes were made.
All tests passed.
No regression signals were detected.
One item touched a sensitive area of the system and needs human review.
Observability checks were clean.
No platform breaks occurred.
Here are the two anomalies worth your attention.
That is useful-but it’s still a lot, especially when you consider I have several agents all doing this. So even this cleaned up synthesis? I predict it fails, too. Still, it’s the best idea I have right now to tackle this… what hits at the root problem.
The simple report respects the actual scarcity in the system, which is not compute and not generation. It is my attention.
The system should not ask me to spend that attention reconstructing what happened from raw artifacts. It should spend its own cycles doing the reconstruction and hand me the result.
This is the crucial design inversion. The agent’s job is not just to create work. Its job is to compress, filter, rank, and justify the small subset of work that rises to human review.
Not output first, review later.
Reviewability first, output underneath it.

What this changes for teams
I think this matters beyond my own setup because a lot of teams are going to run into the same trap as they adopt more autonomous workflows.
They will celebrate that the agents are producing more. More analysis, more tickets, more documents, more proposed features, more code changes, more summaries, more alerts, more plans. For a while, this will feel like acceleration.
Then one of two things will happen.
Either humans will drown in review debt, or they will stop reviewing most of it and quietly let the system become ornamental.
Both outcomes are bad.
In the first case, the team gets slower while insisting it is more automated. In the second case, the team keeps the theater of oversight without actual governance. The pile of output grows, but nobody really knows what is being trusted, what is being ignored, or what standards determine escalation.
That is not autonomy. That is confusion with better formatting.
Teams adopting agentic systems need to think much harder about escalation design than generation design.
What should trigger a human?
What should be batched daily?
What should be summarized weekly?
What should be auto-merged under strict constraints?
What should be killed silently because it is duplicate churn?
What should be tracked only as trend data rather than surfaced as an item?
What evidence should accompany any request for human attention?
Those are operating-model questions, not prompt questions. But they are the ones that determine whether the whole thing becomes useful or unbearable.
The deeper lessonLearn from my scars, you will.
The deeper lesson for me is that agentic engineering forces a redesign not just of execution, but of oversight.
That is the part I had not fully internalized.
I knew agents could make more. I had not really internalized that they could make more than a human should ever directly inspect. I was still carrying an older idea of responsibility, one that equated control with visibility into every artifact.
Now I think that model does not survive contact with scale.
At scale, responsibility cannot mean reading everything. It has to mean designing trustworthy filters, thresholds, tests, and summaries. It has to mean deciding where human judgment is actually irreplaceable and then defending that scarce territory from spam, even when the spam is competent.
This is uncomfortable because it means surrendering a certain style of managerial reassurance. You can no longer tell yourself, “I saw the docs, I reviewed the outputs, I stayed on top of it.” That mode of reassurance becomes impossible once the system is productive enough.
So you need a new basis for trust. What is that-a KPI, a message, something … else entirely? There’s one thing I know…
That trust has to come from process quality: automated testing, escalation logic, duplication controls, confidence scoring, anomaly detection, traceability, and the discipline to say that most artifacts should never be seen by a human at all. We’re going to live in a world with mountains of software whose internals a human has never seen. Whether that software is good, not good, that’s not my point here.
Vast mountains of software sounds extreme until you realize the alternative is to create a machine whose main function is manufacturing guilt.
The standard I care about nowsubject to change
When I look back, the original mistake was simple.
I thought the value of the system was that it could generate a lot of work. Don’t get me wrong-that is very useful. It’s just not the full story.
Now I think the value of the system is whether it can generate work without demanding that I become a full-time reviewer of its existence. Why should I be the final arbiter here? If it works, it works? It still needs a high bar, one that needs clear boundaries. More than a single PRD.
That is a much stricter standard. I’m not sure it’s the right one. It’s an attempt. I have a sense of what matters. It’s about new kinds of filters and controls.
It means I am no longer impressed by sheer output — unless it’s at the gym, but even then I’ll need time to think about it. AI models are impressed by compression-and with good reason. Be impressed by compression. By selectivity. By the quality of the handoff from machine activity to human judgment.
If the system cannot protect attention, it is not really helping, no matter how prolific it is. If you aren’t sure where your attention is wandering, just start taking notes on what your day is spent doing. Human involvement-where did mortal hands get involved.
That is the line I would use now for evaluating any agentic workflow. Not “what did it produce?” but “what did it force a human to do in order to keep it safe and useful?” I think that’s a fair evaluation-where are you having to get involved and why? The systems are capable — the human, me, my time and my attention? Capable but not boundless.
And that is why I think the real bottleneck in agentic engineering is not output.
It is review.